Voice agents
Learn how to build voice agents that can understand audio and respond back in natural language.
Use the OpenAI API and Agents SDK to create powerful, context-aware voice agents for applications like customer support and language tutoring. This guide helps you design and build a voice agent.
Choose the right architecture
OpenAI provides two primary architectures for building voice agents:
[

Speech-to-Speech
Native audio handling by the model using the Realtime API
](/docs/openai/guides/voice-agents?voice-agent-architecture=speech-to-speech)[

Chained
Transforming audio to text and back to use existing models
](/docs/openai/guides/voice-agents?voice-agent-architecture=chained)
Speech-to-speech (realtime) architecture

The multimodal speech-to-speech (S2S) architecture directly processes audio inputs and outputs, handling speech in real time in a single multimodal model, gpt-4o-realtime-preview. The model thinks and responds in speech. It doesn't rely on a transcript of the user's input—it hears emotion and intent, filters out noise, and responds directly in speech. Use this approach for highly interactive, low-latency, conversational use cases.
| Strengths | Best for |
|---|---|
| Low latency interactions | Interactive and unstructured conversations |
| Rich multimodal understanding (audio and text simultaneously) | Language tutoring and interactive learning experiences |
| Natural, fluid conversational flow | Conversational search and discovery |
| Enhanced user experience through vocal context understanding | Interactive customer service scenarios |
Chained architecture
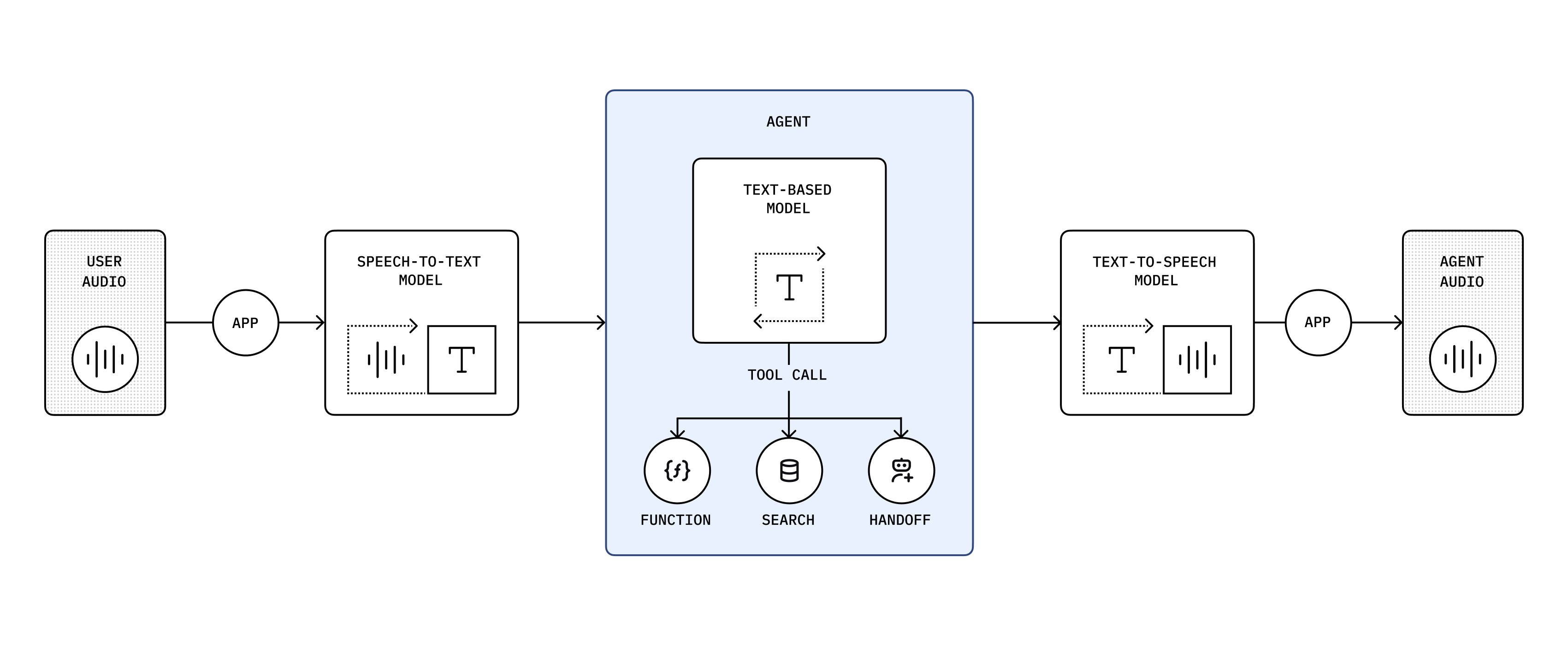
A chained architecture processes audio sequentially, converting audio to text, generating intelligent responses using large language models (LLMs), and synthesizing audio from text. We recommend this predictable architecture if you're new to building voice agents. Both the user input and model's response are in text, so you have a transcript and can control what happens in your application. It's also a reliable way to convert an existing LLM-based application into a voice agent.
You're chaining these models: gpt-4o-transcribe → gpt-4.1 → gpt-4o-mini-tts
| Strengths | Best for |
|---|---|
| High control and transparency | Structured workflows focused on specific user objectives |
| Robust function calling and structured interactions | Customer support |
| Reliable, predictable responses | Sales and inbound triage |
| Support for extended conversational context | Scenarios that involve transcripts and scripted responses |
The following guide below is for building agents using the chained architecture.
To learn more about our recommended speech-to-speech architecture, see the speech-to-speech architecture guide.
Build a voice agent
Use OpenAI's APIs and SDKs to create powerful, context-aware voice agents.
One of the benefits of using a chained architecture is that you can use existing agents for part of your flow and extend them with voice capabilities.
If you are new to building agents, or have already been building with the OpenAI Agents SDK for Python, you can use its built-in VoicePipeline support to extend your existing agents with voice capabilities.
pip install openai-agents[voice]See the Agents SDK voice agents quickstart in GitHub to follow a complete example.
In the example, you'll:
- Run a speech-to-text model to turn audio into text.
- Run your code, which is usually an agentic workflow, to produce a result.
- Run a text-to-speech model to turn the result text back into audio.
Transcribe audio and handle turn detection
When you build your voice agent, you'll need to decide how you want to capture the audio input and transcribe it through a speech-to-text model. Part of this decision is choosing how you want to handle turn detection, or how you'll signal to the model that the user has finished speaking.
There are generally two options:
- Manual turn detection: You determine when the user has finished speaking and pass the completed audio to the speech-to-text model. This works well for "push-to-talk" use cases where there is a clear "start speaking" and "stop speaking" signal or for situations where you want to use your own Voice Activity Detection (VAD) model.
- Automatic turn detection: You pass the raw audio data to our speech-to-text model and use one of our Voice Activity Detection (VAD) models to determine when the user has finished speaking. This is a good option in more conversational use cases where you don't have a clear "start speaking" and "stop speaking" signal such as a phone call.
If you want to leverage our VAD model and automatic turn detection, you can use our gpt-4o-transcribe and gpt-4o-mini-transcribe models using the Realtime Transcription API.
While you could use the Realtime Transcription API also for manual turn detection, you can use the both gpt-4o-transcribe and gpt-4o-mini-transcribe with the Audio Transcription API, without the need to establish and manage a WebSocket connection.
If you are using the OpenAI Agents SDK, this decision is handled for you depending on whether you use the AudioInput() or the StreamedAudioInput() class for your input into the VoicePipeline.
Design your text-based agent
While you can largely re-use your existing text-based agent inside a chained voice agent architecuture, there are some changes that you should consider when using your agent as a voice agent.
Modifying the style of responses
By default most models will have a more chat like style of responses or maybe you've even used some prompting to adhere their response style to adhere to your brand policies. However, when turning that text into speech, certain stylistic choices might not translate well into audio and might actually confuse the model.
For that reason you should add some additional prompting when your agent is used as a voice agent to ensure that the responses are natural sounding and easy to understand.
The actual prompt that works best for you will depend on your use case and brand but here are some examples of things you might want to add to your prompt:
- Use a concise conversational tone with short sentences
- Avoid the use of any complex punctuation or emojis
- Don't use any special formatting like bolding, italicizing or markdown formatting
- Don't use any lists or enumerations
Streaming text
To decreate latency, you also want to make sure that your agent's response tokens are streamed out as soon as they are available. This way you can start generating audio and start playing the first bits of audio back to the user and let the model catch up in the meantime.
Generate audio output
To turn your agent's text responses into natural-sounding speech, use OpenAI's Speech API. The latest model, gpt-4o-mini-tts, delivers high-quality, expressive audio output.
The Speech API is a synchronous HTTP-based service, so you'll need to have the text you want to turn into audio ready before making a request. This means you'll typically wait for your agent to finish generating a response before sending it to the API.
Reducing latency with chunking
To minimize perceived latency, you can implement your own chunking logic: gather tokens from your agent as they stream in, and send them to the Speech API as soon as you have a complete sentence (or another suitable chunk). This allows you to start generating and playing audio before the entire response is ready.
- The trade-off: Larger chunks (e.g., full paragraphs) sound more natural and fluid, but increase wait time before playback begins. Smaller chunks (e.g., single sentences) reduce wait time but may sound less natural when you transition from one chunk to the next.
- For sentence splitting, you can use a simple native implementation (see this example), or leverage more advanced NLP models for higher accuracy—though these may introduce additional latency.
Audio streaming and formats
The Speech API streams audio as soon as it's ready. For the lowest latency, use the wav or pcm output formats, as these are faster to generate and transmit than formats like mp3 or opus.
If you are using the OpenAI Agents SDK, both basic sentence chunking and using pcm are automatically handled for you.
Customizing voice and tone
You can use the instructions field in the Speech API to guide the model's voice, tone, and delivery. This allows you to match the agent's personality to your use case. For inspiration, see openai.fm.
Here are two example instruction prompts:
Patient teacher
Accent/Affect: Warm, refined, and gently instructive, reminiscent
of a friendly art instructor.
Tone: Calm, encouraging, and articulate, clearly describing each
step with patience.
Pacing: Slow and deliberate, pausing often to allow the listener
to follow instructions comfortably.
Emotion: Cheerful, supportive, and pleasantly enthusiastic;
convey genuine enjoyment and appreciation of art.
Pronunciation: Clearly articulate artistic terminology (e.g.,
"brushstrokes," "landscape," "palette") with gentle emphasis.
Personality Affect: Friendly and approachable with a hint of
sophistication; speak confidently and reassuringly, guiding
users through each painting step patiently and warmly.Fitness instructor
Voice: High-energy, upbeat, and encouraging, projecting
enthusiasm and motivation.
Punctuation: Short, punchy sentences with strategic pauses
to maintain excitement and clarity.
Delivery: Fast-paced and dynamic, with rising intonation to
build momentum and keep engagement high.
Phrasing: Action-oriented and direct, using motivational
cues to push participants forward.
Tone: Positive, energetic, and empowering, creating an
atmosphere of encouragement and achievement.For more details and advanced options, see the Text-to-Speech guide.