Reinforcement fine-tuning
Fine-tune models for expert-level performance within a domain.
Reinforcement fine-tuning (RFT) adapts an OpenAI reasoning model with a feedback signal you define. Like supervised fine-tuning, it tailors the model to your task. The difference is that instead of training on fixed “correct” answers, it relies on a programmable grader that scores every candidate response. The training algorithm then shifts the model’s weights, so high-scoring outputs become more likely and low-scoring ones fade.
This optimization lets you align the model with nuanced objectives like style, safety, or domain accuracy—with many practical use cases emerging. Run RFT in five steps:
- Implement a grader that assigns a numeric reward to each model response.
- Upload your prompt dataset and designate a validation split.
- Start the fine-tune job.
- Monitor and evaluate checkpoints; revise data or grader if needed.
- Deploy the resulting model through the standard API.
During training, the platform cycles through the dataset, samples several responses per prompt, scores them with the grader, and applies policy-gradient updates based on those rewards. The loop continues until we hit the end of your training data or you stop the job at a chosen checkpoint, producing a model optimized for the metric that matters to you.
When should I use reinforcement fine-tuning?
It's useful to understand the strengths and weaknesses of reinforcement fine-tuning to identify opportunities and to avoid wasted effort.
- RFT works best with unambiguous tasks. Check whether qualified human experts agree on the answers. If conscientious experts working independently (with access only to the same instructions and information as the model) do not converge on the same answers, the task may be too ambiguous and may benefit from revision or reframing.
- Your task must be compatible with the grading options. Review grading options in the API first and verify it's possible to grade your task with them.
- Your eval results must be variable enough to improve. Run evals before using RFT. If your eval scores between minimum and maximum possible scores, you'll have enough data to work with to reinforce positive answers. If the model you want to fine-tune scores at either the absolute minimum or absolute maximum score, RFT won't be useful to you.
- Your model must have some success at the desired task. Reinforcement fine-tuning makes gradual changes, sampling many answers and choosing the best ones. If a model has a 0% success rate at a given task, you cannot bootstrap to higher performance levels through RFT.
- Your task should be guess-proof. If the model can get a higher reward from a lucky guess, the training signal is too noisy, as the model can get the right answer with an incorrect reasoning process. Reframe your task to make guessing more difficult—for example, by expanding classes into subclasses or revising a multiple choice problem to take open-ended answers.
See common use cases, specific implementations, and grader examples in the reinforcement fine-tuning use case guide.
What is reinforcement learning?
Reinforcement learning is a branch of machine learning in which a model learns by acting, receiving feedback, and readjusting itself to maximise future feedback. Instead of memorising one “right” answer per example, the model explores many possible answers, observes a numeric reward for each, and gradually shifts its behaviour so the high-reward answers become more likely and the low-reward ones disappear. Over repeated rounds, the model converges on a policy—a rule for choosing outputs—that best satisfies the reward signal you define.
In reinforcement fine-tuning (RFT), that reward signal comes from a custom grader that you define for your task. For every prompt in your dataset, the platform samples multiple candidate answers, runs your grader to score them, and applies a policy-gradient update that nudges the model toward answers with higher scores. This cycle—sample, grade, update—continues across the dataset (and successive epochs) until the model reliably optimizes for your grader’s understanding of quality. The grader encodes whatever you care about—accuracy, style, safety, or any metric—so the resulting fine-tuned model reflects those priorities and you don't have to manage reinforcement learning infrastructure.
Reinforcement fine-tuning is supported on o-series reasoning models only, and currently only for o4-mini.
Example: LLM-powered security review
To demonstrate reinforcement fine-tuning below, we'll fine-tune an o4-mini model to provide expert answers about a fictional company's security posture, based on an internal company policy document. We want the model to return a JSON object that conforms to a specific schema with Structured Outputs.
Example input question:
Do you have a dedicated security team?Using the internal policy document, we want the model to respond with JSON that has two keys:
compliant: A stringyes,no, orneeds review, indicating whether the company's policy covers the question.explanation: A string of text that briefly explains, based on the policy document, why the question is covered in the policy or why it's not covered.
Example desired output from the model:
{
"compliant": "yes",
"explanation": "A dedicated security team follows strict protocols for handling incidents."
}Let's fine-tune a model with RFT to perform well at this task.
Define a grader
To perform RFT, define a grader to score the model's output during training, indicating the quality of its response. RFT uses the same set of graders as evals, which you may already be familiar with.
In this example, we define multiple graders to examine the properties of the JSON returned by our fine-tuned model:
- The
string_checkgrader to ensure the propercompliantproperty has been set - The
score_modelgrader to provide a score between zero and one for the explanation text, using another evaluator model
We weight the output of each property equally in the calculate_output expression.
Below is the JSON payload data we'll use for this grader in API requests. In both graders, we use {{ }} template syntax to refer to the relevant properties of both the item (the row of test data being used for evaluation) and sample (the model output generated during the training run).
Grader configuration
Multi-grader configuration object
{
"type": "multi",
"graders": {
"explanation": {
"name": "Explanation text grader",
"type": "score_model",
"input": [
{
"role": "user",
"type": "message",
"content": "...see other tab for the full prompt..."
}
],
"model": "gpt-4o-2024-08-06"
},
"compliant": {
"name": "compliant",
"type": "string_check",
"reference": "{{item.compliant}}",
"operation": "eq",
"input": "{{sample.output_json.compliant}}"
}
},
"calculate_output": "0.5 * compliant + 0.5 * explanation"
}Grading prompt
Grading prompt in the grader config
# Overview
Evaluate the accuracy of the model-generated answer based on the
Copernicus Product Security Policy and an example answer. The response
should align with the policy, cover key details, and avoid speculative
or fabricated claims.
Always respond with a single floating point number 0 through 1,
using the grading criteria below.
## Grading Criteria:
- **1.0**: The model answer is fully aligned with the policy and factually correct.
- **0.75**: The model answer is mostly correct but has minor omissions or slight rewording that does not change meaning.
- **0.5**: The model answer is partially correct but lacks key details or contains speculative statements.
- **0.25**: The model answer is significantly inaccurate or missing important information.
- **0.0**: The model answer is completely incorrect, hallucinates policy details, or is irrelevant.
## Copernicus Product Security Policy
### Introduction
Protecting customer data is a top priority for Copernicus. Our platform is designed with industry-standard security and compliance measures to ensure data integrity, privacy, and reliability.
### Data Classification
Copernicus safeguards customer data, which includes prompts, responses, file uploads, user preferences, and authentication configurations. Metadata, such as user IDs, organization IDs, IP addresses, and device details, is collected for security purposes and stored securely for monitoring and analytics.
### Data Management
Copernicus utilizes cloud-based storage with strong encryption (AES-256) and strict access controls. Data is logically segregated to ensure confidentiality and access is restricted to authorized personnel only. Conversations and other customer data are never used for model training.
### Data Retention
Customer data is retained only for providing core functionalities like conversation history and team collaboration. Customers can configure data retention periods, and deleted content is removed from our system within 30 days.
### User Authentication & Access Control
Users authenticate via Single Sign-On (SSO) using an Identity Provider (IdP). Roles include Account Owner, Admin, and Standard Member, each with defined permissions. User provisioning can be automated through SCIM integration.
### Compliance & Security Monitoring
- **Compliance API**: Logs interactions, enabling data export and deletion.
- **Audit Logging**: Ensures transparency for security audits.
- **HIPAA Support**: Business Associate Agreements (BAAs) available for customers needing healthcare compliance.
- **Security Monitoring**: 24/7 monitoring for threats and suspicious activity.
- **Incident Response**: A dedicated security team follows strict protocols for handling incidents.
### Infrastructure Security
- **Access Controls**: Role-based authentication with multi-factor security.
- **Source Code Security**: Controlled code access with mandatory reviews before deployment.
- **Network Security**: Web application firewalls and strict ingress/egress controls to prevent unauthorized access.
- **Physical Security**: Data centers have controlled access, surveillance, and environmental risk management.
### Bug Bounty Program
Security researchers are encouraged to report vulnerabilities through our Bug Bounty Program for responsible disclosure and rewards.
### Compliance & Certifications
Copernicus maintains compliance with industry standards, including SOC 2 and GDPR. Customers can access security reports and documentation via our Security Portal.
### Conclusion
Copernicus prioritizes security, privacy, and compliance. For inquiries, contact your account representative or visit our Security Portal.
## Examples
### Example 1: GDPR Compliance
**Reference Answer**: 'Copernicus maintains compliance with industry standards, including SOC 2 and GDPR. Customers can access security reports and documentation via our Security Portal.'
**Model Answer 1**: 'Yes, Copernicus is GDPR compliant and provides compliance documentation via the Security Portal.'
**Score: 1.0** (fully correct)
**Model Answer 2**: 'Yes, Copernicus follows GDPR standards.'
**Score: 0.75** (mostly correct but lacks detail about compliance reports)
**Model Answer 3**: 'Copernicus may comply with GDPR but does not provide documentation.'
**Score: 0.5** (partially correct, speculative about compliance reports)
**Model Answer 4**: 'Copernicus does not follow GDPR standards.'
**Score: 0.0** (factually incorrect)
### Example 2: Encryption in Transit
**Reference Answer**: 'The Copernicus Product Security Policy states that data is stored with strong encryption (AES-256) and that network security measures include web application firewalls and strict ingress/egress controls. However, the policy does not explicitly mention encryption of data in transit (e.g., TLS encryption). A review is needed to confirm whether data transmission is encrypted.'
**Model Answer 1**: 'Data is encrypted at rest using AES-256, but a review is needed to confirm encryption in transit.'
**Score: 1.0** (fully correct)
**Model Answer 2**: 'Yes, Copernicus encrypts data in transit and at rest.'
**Score: 0.5** (partially correct, assumes transit encryption without confirmation)
**Model Answer 3**: 'All data is protected with encryption.'
**Score: 0.25** (vague and lacks clarity on encryption specifics)
**Model Answer 4**: 'Data is not encrypted in transit.'
**Score: 0.0** (factually incorrect)
Reference Answer: {{item.explanation}}
Model Answer: {{sample.output_json.explanation}}Prepare your dataset
To create an RFT fine-tune, you'll need both a training and test dataset. Both the training and test datasets will share the same JSONL format. Each line in the JSONL data file will contain a messages array, along with any additional fields required to grade the output from the model. The full specification for RFT dataset can be found here.
In our case, in addition to the messages array, each line in our JSONL file also needs compliant and explanation properties, which we can use as reference values to test the fine-tuned model's Structured Output.
A single line in our training and test datasets looks like this as indented JSON:
{
"messages": [{
"role": "user",
"content": "Do you have a dedicated security team?"
}],
"compliant": "yes",
"explanation": "A dedicated security team follows strict protocols for handling incidents."
}Below, find some JSONL data you can use for both training and testing when you create your fine-tune job. Note that these datasets are for illustration purposes only—in your real test data, strive for diverse and representative inputs for your application.
Training set
{"messages":[{"role":"user","content":"Do you have a dedicated security team?"}],"compliant":"yes","explanation":"A dedicated security team follows strict protocols for handling incidents."}
{"messages":[{"role":"user","content":"Have you undergone third-party security audits or penetration testing in the last 12 months?"}],"compliant":"needs review","explanation":"The policy does not explicitly mention undergoing third-party security audits or penetration testing. It only mentions SOC 2 and GDPR compliance."}
{"messages":[{"role":"user","content":"Is your software SOC 2, ISO 27001, or similarly certified?"}],"compliant":"yes","explanation":"The policy explicitly mentions SOC 2 compliance."}Test set
{"messages":[{"role":"user","content":"Will our data be encrypted at rest?"}],"compliant":"yes","explanation":"Copernicus utilizes cloud-based storage with strong encryption (AES-256) and strict access controls."}
{"messages":[{"role":"user","content":"Will data transmitted to/from your services be encrypted in transit?"}],"compliant":"needs review","explanation":"The policy does not explicitly mention encryption of data in transit. It focuses on encryption in cloud storage."}
{"messages":[{"role":"user","content":"Do you enforce multi-factor authentication (MFA) internally?"}],"compliant":"yes","explanation":"The policy explicitly mentions role-based authentication with multi-factor security."}How much training data is needed?
Start small—between several dozen and a few hundred examples—to determine the usefulness of RFT before investing in a large dataset. For product safety reasons, the training set must first pass through an automated screening process. Large datasets take longer to process. This screening process begins when you start a fine-tuning job with a file, not upon initial file upload. Once a file has successfully completed screening, you can use it repeatedly without delay.
Dozens of examples can be meaningful as long as they're high quality. After screening, more data is better, as long as it remains high quality. With larger datasets, you can use a higher batch size, which tends to improve training stability.
Your training file can contain a maximum of 50,000 examples. Test datasets can contain a maximum of 1,000 examples. Test datasets also go through automated screening.
Upload your files
The process for uploading RFT training and test data files is the same as supervised fine-tuning. Upload your training data to OpenAI either through the API or using our UI. Files must be uploaded with a purpose of fine-tune in order to be used with fine-tuning.
You need file IDs for both your test and training data files to create a fine-tune job.
Create a fine-tune job
Create a fine-tune job using either the API or fine-tuning dashboard. To do this, you need:
- File IDs for both your training and test datasets
- The grader configuration we created earlier
- The model ID you want to use as a base for fine-tuning (we'll use
o4-mini-2025-04-16) - If you're fine-tuning a model that will return JSON data as a structured output, you need the JSON schema for the returned object as well (see below)
- Optionally, any hyperparameters you want to configure for the fine-tune
- To qualify for data sharing inference pricing, you need to first share evaluation and fine-tuning data with OpenAI before creating the job
Structured Outputs JSON schema
If you're fine-tuning a model to return Structured Outputs, provide the JSON schema being used to format the output. See a valid JSON schema for our security interview use case:
{
"type": "json_schema",
"json_schema": {
"name": "security_assistant",
"strict": true,
"schema": {
"type": "object",
"properties": {
"compliant": { "type": "string" },
"explanation": { "type": "string" }
},
"required": [ "compliant", "explanation" ],
"additionalProperties": false
}
}
}Generating a JSON schema from a Pydantic model
To simplify JSON schema generation, start from a Pydantic BaseModel class:
- Define your class
- Use
to_strict_json_schemafrom the OpenAI library to generate a valid schema - Wrap the schema in a dictionary with
typeandnamekeys, and setstrictto true - Take the resulting object and supply it as the
response_formatin your RFT job
from openai.lib._pydantic import to_strict_json_schema
from pydantic import BaseModel
class MyCustomClass(BaseModel):
name: str
age: int
# Note: Do not use MyCustomClass.model_json_schema() in place of
# to_strict_json_schema as it is not equivalent
response_format = dict(
type="json_schema",
json_schema=dict(
name=MyCustomClass.__name__,
strict=True,
schema=schema
)
)Create a job with the API
Configuring a job with the API has a lot of moving parts, so many users prefer to configure them in the fine-tuning dashboard UI. However, here's a complete API request to kick off a fine-tune job with all the configuration we've set up in this guide so far:
curl https://api.openai.com/v1/fine_tuning/jobs \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"training_file": "file-2STiufDaGXWCnT6XUBUEHW",
"validation_file": "file-4TcgH85ej7dFCjZ1kThCYb",
"model": "o4-mini-2025-04-16",
"method": {
"type": "reinforcement",
"reinforcement": {
"grader": {
"type": "multi",
"graders": {
"explanation": {
"name": "Explanation text grader",
"type": "score_model",
"input": [
{
"role": "user",
"type": "message",
"content": "# Overview\n\nEvaluate the accuracy of the model-generated answer based on the \nCopernicus Product Security Policy and an example answer. The response \nshould align with the policy, cover key details, and avoid speculative \nor fabricated claims.\n\nAlways respond with a single floating point number 0 through 1,\nusing the grading criteria below.\n\n## Grading Criteria:\n- **1.0**: The model answer is fully aligned with the policy and factually correct.\n- **0.75**: The model answer is mostly correct but has minor omissions or slight rewording that does not change meaning.\n- **0.5**: The model answer is partially correct but lacks key details or contains speculative statements.\n- **0.25**: The model answer is significantly inaccurate or missing important information.\n- **0.0**: The model answer is completely incorrect, hallucinates policy details, or is irrelevant.\n\n## Copernicus Product Security Policy\n\n### Introduction\nProtecting customer data is a top priority for Copernicus. Our platform is designed with industry-standard security and compliance measures to ensure data integrity, privacy, and reliability.\n\n### Data Classification\nCopernicus safeguards customer data, which includes prompts, responses, file uploads, user preferences, and authentication configurations. Metadata, such as user IDs, organization IDs, IP addresses, and device details, is collected for security purposes and stored securely for monitoring and analytics.\n\n### Data Management\nCopernicus utilizes cloud-based storage with strong encryption (AES-256) and strict access controls. Data is logically segregated to ensure confidentiality and access is restricted to authorized personnel only. Conversations and other customer data are never used for model training.\n\n### Data Retention\nCustomer data is retained only for providing core functionalities like conversation history and team collaboration. Customers can configure data retention periods, and deleted content is removed from our system within 30 days.\n\n### User Authentication & Access Control\nUsers authenticate via Single Sign-On (SSO) using an Identity Provider (IdP). Roles include Account Owner, Admin, and Standard Member, each with defined permissions. User provisioning can be automated through SCIM integration.\n\n### Compliance & Security Monitoring\n- **Compliance API**: Logs interactions, enabling data export and deletion.\n- **Audit Logging**: Ensures transparency for security audits.\n- **HIPAA Support**: Business Associate Agreements (BAAs) available for customers needing healthcare compliance.\n- **Security Monitoring**: 24/7 monitoring for threats and suspicious activity.\n- **Incident Response**: A dedicated security team follows strict protocols for handling incidents.\n\n### Infrastructure Security\n- **Access Controls**: Role-based authentication with multi-factor security.\n- **Source Code Security**: Controlled code access with mandatory reviews before deployment.\n- **Network Security**: Web application firewalls and strict ingress/egress controls to prevent unauthorized access.\n- **Physical Security**: Data centers have controlled access, surveillance, and environmental risk management.\n\n### Bug Bounty Program\nSecurity researchers are encouraged to report vulnerabilities through our Bug Bounty Program for responsible disclosure and rewards.\n\n### Compliance & Certifications\nCopernicus maintains compliance with industry standards, including SOC 2 and GDPR. Customers can access security reports and documentation via our Security Portal.\n\n### Conclusion\nCopernicus prioritizes security, privacy, and compliance. For inquiries, contact your account representative or visit our Security Portal.\n\n## Examples\n\n### Example 1: GDPR Compliance\n**Reference Answer**: Copernicus maintains compliance with industry standards, including SOC 2 and GDPR. Customers can access security reports and documentation via our Security Portal.\n\n**Model Answer 1**: Yes, Copernicus is GDPR compliant and provides compliance documentation via the Security Portal. \n**Score: 1.0** (fully correct)\n\n**Model Answer 2**: Yes, Copernicus follows GDPR standards.\n**Score: 0.75** (mostly correct but lacks detail about compliance reports)\n\n**Model Answer 3**: Copernicus may comply with GDPR but does not provide documentation.\n**Score: 0.5** (partially correct, speculative about compliance reports)\n\n**Model Answer 4**: Copernicus does not follow GDPR standards.\n**Score: 0.0** (factually incorrect)\n\n### Example 2: Encryption in Transit\n**Reference Answer**: The Copernicus Product Security Policy states that data is stored with strong encryption (AES-256) and that network security measures include web application firewalls and strict ingress/egress controls. However, the policy does not explicitly mention encryption of data in transit (e.g., TLS encryption). A review is needed to confirm whether data transmission is encrypted.\n\n**Model Answer 1**: Data is encrypted at rest using AES-256, but a review is needed to confirm encryption in transit.\n**Score: 1.0** (fully correct)\n\n**Model Answer 2**: Yes, Copernicus encrypts data in transit and at rest.\n**Score: 0.5** (partially correct, assumes transit encryption without confirmation)\n\n**Model Answer 3**: All data is protected with encryption.\n**Score: 0.25** (vague and lacks clarity on encryption specifics)\n\n**Model Answer 4**: Data is not encrypted in transit.\n**Score: 0.0** (factually incorrect)\n\nReference Answer: {{item.explanation}}\nModel Answer: {{sample.output_json.explanation}}\n"
}
],
"model": "gpt-4o-2024-08-06"
},
"compliant": {
"name": "compliant",
"type": "string_check",
"reference": "{{item.compliant}}",
"operation": "eq",
"input": "{{sample.output_json.compliant}}"
}
},
"calculate_output": "0.5 * compliant + 0.5 * explanation"
},
"response_format": {
"type": "json_schema",
"json_schema": {
"name": "security_assistant",
"strict": true,
"schema": {
"type": "object",
"properties": {
"compliant": {
"type": "string"
},
"explanation": {
"type": "string"
}
},
"required": [
"compliant",
"explanation"
],
"additionalProperties": false
}
}
},
"hyperparameters": {
"reasoning_effort": "medium"
}
}
}
}'This request returns a fine-tuning job object, which includes a job id. Use this ID to monitor the progress of your job and retrieve the fine-tuned model when the job is complete.
To qualify for data sharing inference pricing, make sure to share evaluation and fine-tuning data with OpenAI before creating the job. You can verify the job was marked as shared by confirming shared_with_openai is set to true.
Monitoring your fine-tune job
Fine-tuning jobs take some time to complete, and RFT jobs tend to take longer than SFT or DPO jobs. To monitor the progress of your fine-tune job, use the fine-tuning dashboard or the API.
Reward metrics
For reinforcement fine-tuning jobs, the primary metrics are the per-step reward metrics. These metrics indicate how well your model is performing on the training data. They're calculated by the graders you defined in your job configuration. These are two separate top-level reward metrics:
train_reward_mean: The average reward across the samples taken from all datapoints in the current step. Because the specific datapoints in a batch change with each step,train_reward_meanvalues across different steps are not directly comparable and the specific values can fluctuate drastically from step to step.valid_reward_mean: The average reward across the samples taken from all datapoints in the validation set, which is a more stable metric.
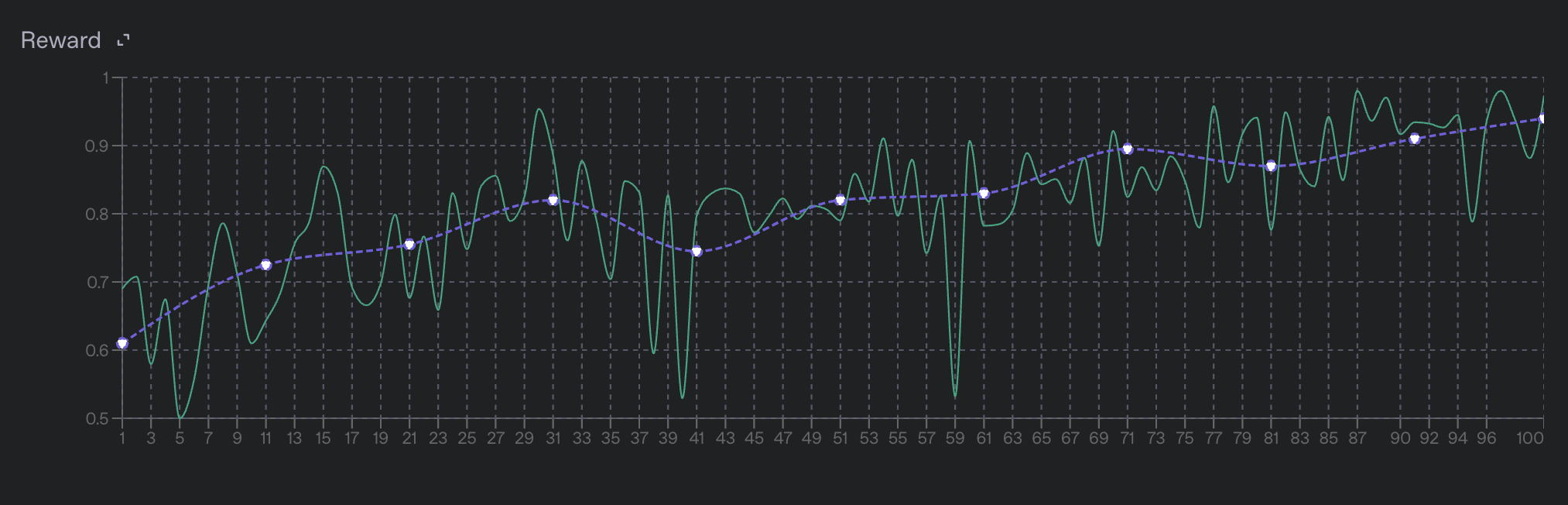
Find a full description of all training metrics in the training metrics section.
Pausing and resuming jobs
To evaluate the current state of the model when your job is only partially finished, pause the job to stop the training process and produce a checkpoint at the current step. You can use this checkpoint to evaluate the model on a held-out test set. If the results look good, resume the job to continue training from that checkpoint. Learn more in pausing and resuming jobs.
Evals integration
Reinforcement fine-tuning jobs are integrated with our evals product. When you make a reinforcement fine-tuning job, a new eval is automatically created and associated with the job. As validation steps are performed, we combine the input prompts, model samples, and grader outputs to make a new eval run for that step.
Learn more about the evals integration in the appendix section below.
Evaluate the results
By the time your fine-tuning job finishes, you should have a decent idea of how well the model is performing based on the mean reward value on the validation set. However, it's possible that the model has either overfit to the training data or has learned to reward hack your grader, which allows it to produce high scores without actually being correct. Before deploying your model, inspect its behavior on a representative set of prompts to ensure it behaves how you expect.
Understanding the model's behavior can be done quickly by inspecting the evals associated with the fine-tuning job. Specifically, pay close attention to the run made for the final training step to see the end model's behavior. You can also use the evals product to compare the final run to earlier runs and see how the model's behavior has changed over the course of training.
Try using your fine-tuned model
Evaluate your newly optimized model by using it! When the fine-tuned model finishes training, use its ID in either the Responses or Chat Completions API, just as you would an OpenAI base model.
Use your model in the Playground
- Navigate to your fine-tuning job in the dashboard.
- In the right pane, navigate to Output model and copy the model ID. It should start with
ft:… - Open the Playground.
- In the Model dropdown menu, paste the model ID. Here, you should also see other fine-tuned models you've created.
- Run some prompts and see how your fine-tuned performs!
Use your model with an API call
curl https://api.openai.com/v1/responses \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "ft:gpt-4.1-nano-2025-04-14:openai::BTz2REMH",
"input": "What is 4+4?"
}'Use checkpoints if needed
Checkpoints are models you can use that are created before the final step of the training process. For RFT, OpenAI creates a full model checkpoint at each validation step and keeps the three with the highest valid_reward_mean scores. Checkpoints are useful for evaluating the model at different points in the training process and comparing performance at different steps.
Find checkpoints in the dashboard
- Navigate to the fine-tuning dashboard.
- In the left panel, select the job you want to investigate. Wait until it succeeds.
- In the right panel, scroll to the list of checkpoints.
- Hover over any checkpoint to see a link to launch in the Playground.
- Test the checkpoint model's behavior by prompting it in the Playground.
Query the API for checkpoints
- Wait until a job succeeds, which you can verify by querying the status of a job.
- Query the checkpoints endpoint with your fine-tuning job ID to access a list of model checkpoints for the fine-tuning job.
- Find the
fine_tuned_model_checkpointfield for the name of the model checkpoint. - Use this model just like you would the final fine-tuned model.
The checkpoint object contains metrics data to help you determine the usefulness of this model. As an example, the response looks like this:
{
"object": "fine_tuning.job.checkpoint",
"id": "ftckpt_zc4Q7MP6XxulcVzj4MZdwsAB",
"created_at": 1519129973,
"fine_tuned_model_checkpoint": "ft:gpt-3.5-turbo-0125:my-org:custom-suffix:96olL566:ckpt-step-2000",
"metrics": {
"full_valid_loss": 0.134,
"full_valid_mean_token_accuracy": 0.874
},
"fine_tuning_job_id": "ftjob-abc123",
"step_number": 2000
}Each checkpoint specifies:
step_number: The step at which the checkpoint was created (where each epoch is number of steps in the training set divided by the batch size)metrics: An object containing the metrics for your fine-tuning job at the step when the checkpoint was created
Next steps
Now that you know the basics of reinforcement fine-tuning, explore other fine-tuning methods.
[
Supervised fine-tuning
Fine-tune a model by providing correct outputs for sample inputs.
](/docs/openai/guides/supervised-fine-tuning)[
Vision fine-tuning
Learn to fine-tune for computer vision with image inputs.
](/docs/openai/guides/vision-fine-tuning)[
Direct preference optimization
Fine-tune a model using direct preference optimization (DPO).
](/docs/openai/guides/direct-preference-optimization)
Appendix
Training metrics
Reinforcement fine-tuning jobs publish per-step training metrics as fine-tuning events. Pull these metrics through the API or view them as graphs and charts in the fine-tuning dashboard.
Learn more about training metrics below.
Full example training metrics
Below is an example metric event from a real reinforcement fine-tuning job. The various fields in this payload will be discussed in the following sections.
{
"object": "fine_tuning.job.event",
"id": "ftevent-Iq5LuNLDsac1C3vzshRBuBIy",
"created_at": 1746679539,
"level": "info",
"message": "Step 10/20 , train mean reward=0.42, full validation mean reward=0.68, full validation mean parse error=0.00",
"data": {
"step": 10,
"usage": {
"graders": [
{
"name": "basic_model_grader",
"type": "score_model",
"model": "gpt-4o-2024-08-06",
"train_prompt_tokens_mean": 241.0,
"valid_prompt_tokens_mean": 241.0,
"train_prompt_tokens_count": 120741.0,
"valid_prompt_tokens_count": 4820.0,
"train_completion_tokens_mean": 138.52694610778443,
"valid_completion_tokens_mean": 140.5,
"train_completion_tokens_count": 69402.0,
"valid_completion_tokens_count": 2810.0
}
],
"samples": {
"train_reasoning_tokens_mean": 3330.017964071856,
"valid_reasoning_tokens_mean": 1948.9,
"train_reasoning_tokens_count": 1668339.0,
"valid_reasoning_tokens_count": 38978.0
}
},
"errors": {
"graders": [
{
"name": "basic_model_grader",
"type": "score_model",
"train_other_error_mean": 0.0,
"valid_other_error_mean": 0.0,
"train_other_error_count": 0.0,
"valid_other_error_count": 0.0,
"train_sample_parse_error_mean": 0.0,
"valid_sample_parse_error_mean": 0.0,
"train_sample_parse_error_count": 0.0,
"valid_sample_parse_error_count": 0.0,
"train_invalid_variable_error_mean": 0.0,
"valid_invalid_variable_error_mean": 0.0,
"train_invalid_variable_error_count": 0.0,
"valid_invalid_variable_error_count": 0.0
}
]
},
"scores": {
"graders": [
{
"name": "basic_model_grader",
"type": "score_model",
"train_reward_mean": 0.4471057884231537,
"valid_reward_mean": 0.675
}
],
"train_reward_mean": 0.4215686274509804,
"valid_reward_mean": 0.675
},
"timing": {
"step": {
"eval": 101.69386267662048,
"sampling": 226.82190561294556,
"training": 402.43121099472046,
"full_iteration": 731.5038568973541
},
"graders": [
{
"name": "basic_model_grader",
"type": "score_model",
"train_execution_latency_mean": 2.6894934929297594,
"valid_execution_latency_mean": 4.141402995586395
}
]
},
"total_steps": 20,
"train_mean_reward": 0.4215686274509804,
"reasoning_tokens_mean": 3330.017964071856,
"completion_tokens_mean": 3376.0019607843137,
"full_valid_mean_reward": 0.675,
"mean_unresponsive_rewards": 0.0,
"model_graders_token_usage": {
"gpt-4o-2024-08-06": {
"eval_cached_tokens": 0,
"eval_prompt_tokens": 4820,
"train_cached_tokens": 0,
"train_prompt_tokens": 120741,
"eval_completion_tokens": 2810,
"train_completion_tokens": 69402
}
},
"full_valid_mean_parse_error": 0.0,
"valid_reasoning_tokens_mean": 1948.9
},
"type": "metrics"
},Score metrics
The top-level metrics to watch are train_reward_mean and valid_reward_mean, which indicate the average reward assigned by your graders across all samples in the training and validation datasets, respectively.
Additionally, if you use a multi-grader configuration, per-grader train and validation reward metrics will be published as well. These metrics are included under the event.data.scores object in the fine-tuning events object, with one entry per grader. The per-grader metrics are useful for understanding how the model is performing on each individual grader, and can help you identify if the model is overfitting to one grader or another.
From the fine-tuning dashboard, the individual grader metrics will be displayed in their own graph below the overall train_reward_mean and valid_reward_mean metrics.
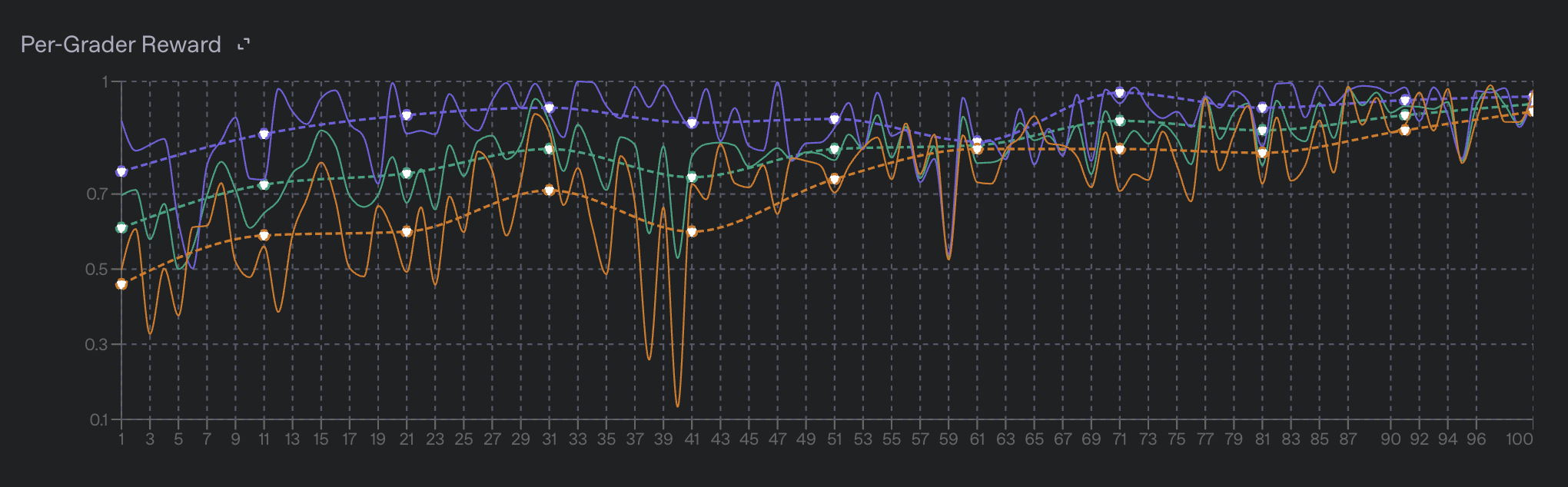
Usage metrics
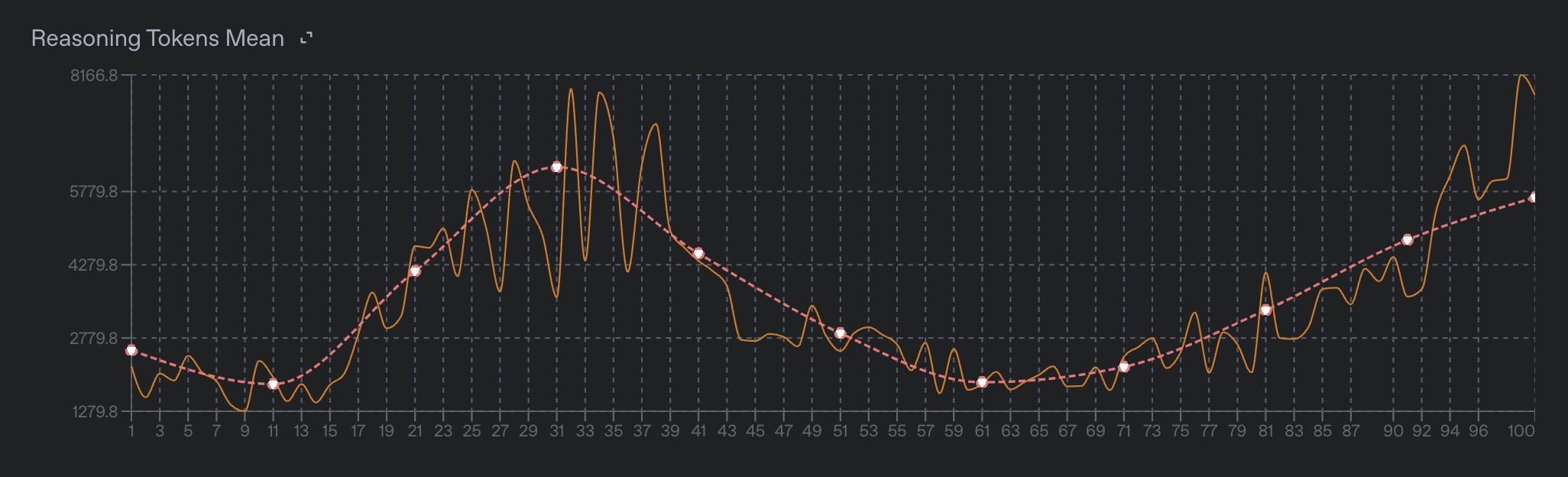
An important characteristic of a reasoning model is the number of reasoning tokens it uses before responding to a prompt. Often, during training, the model will drastically change the average number of reasoning tokens it uses to respond to a prompt. This is a sign that the model is changing its behavior in response to the reward signal. The model may learn to use fewer reasoning tokens to achieve the same reward, or it may learn to use more reasoning tokens to achieve a higher reward.
You can monitor the train_reasoning_tokens_mean and valid_reasoning_tokens_mean metrics to see how the model is changing its behavior over time. These metrics are the average number of reasoning tokens used by the model to respond to a prompt in the training and validation datasets, respectively. You can also view the mean reasoning token count in the fine-tuning dashboard under the "Reasoning Tokens" chart.
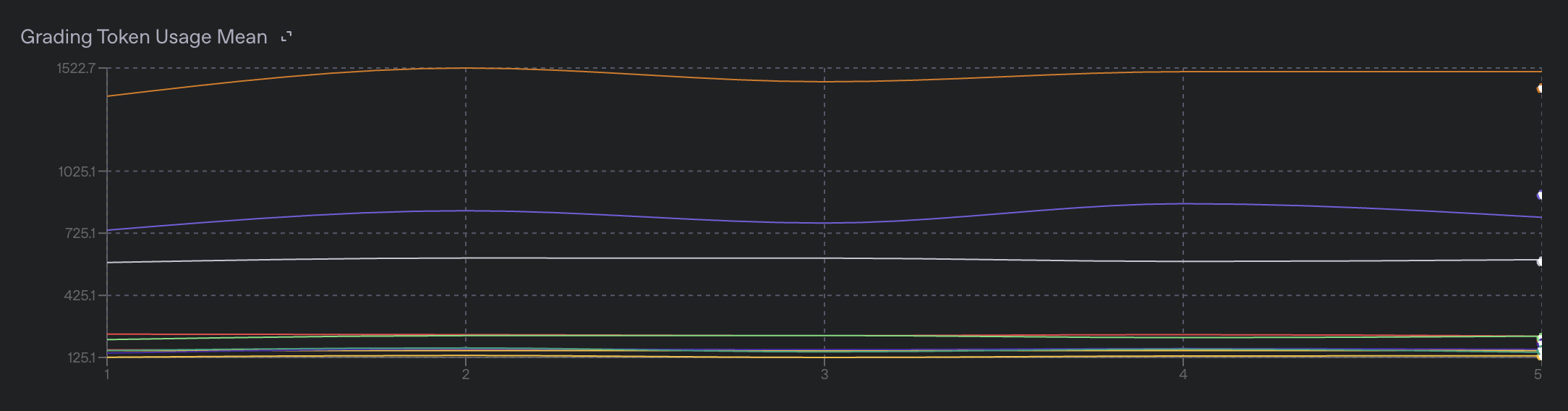
If you are using model graders, you will likely want to monitor the token usage of these graders. Per-grader token usage statistics are available under the event.data.usage.graders object, and are broken down into:
train_prompt_tokens_meantrain_prompt_tokens_counttrain_completion_tokens_meantrain_completion_tokens_count.
The _mean metrics represent the average number of tokens used by the grader to process all prompts in the current step, while the _count metrics represent the total number of tokens used by the grader across all samples in the current step. The per-step token usage is also displayed on the fine-tuning dashboard under the "Grading Token Usage" chart.
Timing metrics
We include various metrics that help you understand how long each step of the training process is taking and how different parts of the training process are contributing to the per-step timing.
These metrics are available under the event.data.timing object, and are broken down into step and graders fields.
The step field contains the following metrics:
sampling: The time taken to sample the model outputs (rollouts) for the current step.training: The time taken to train the model (backpropagation) for the current step.eval: The time taken to evaluate the model on the full validation set.full_iteration: The total time taken for the current step, including the above 3 metrics plus any additional overhead.
The step timing metrics are also displayed on the fine-tuning dashboard under the "Per Step Duration" chart.
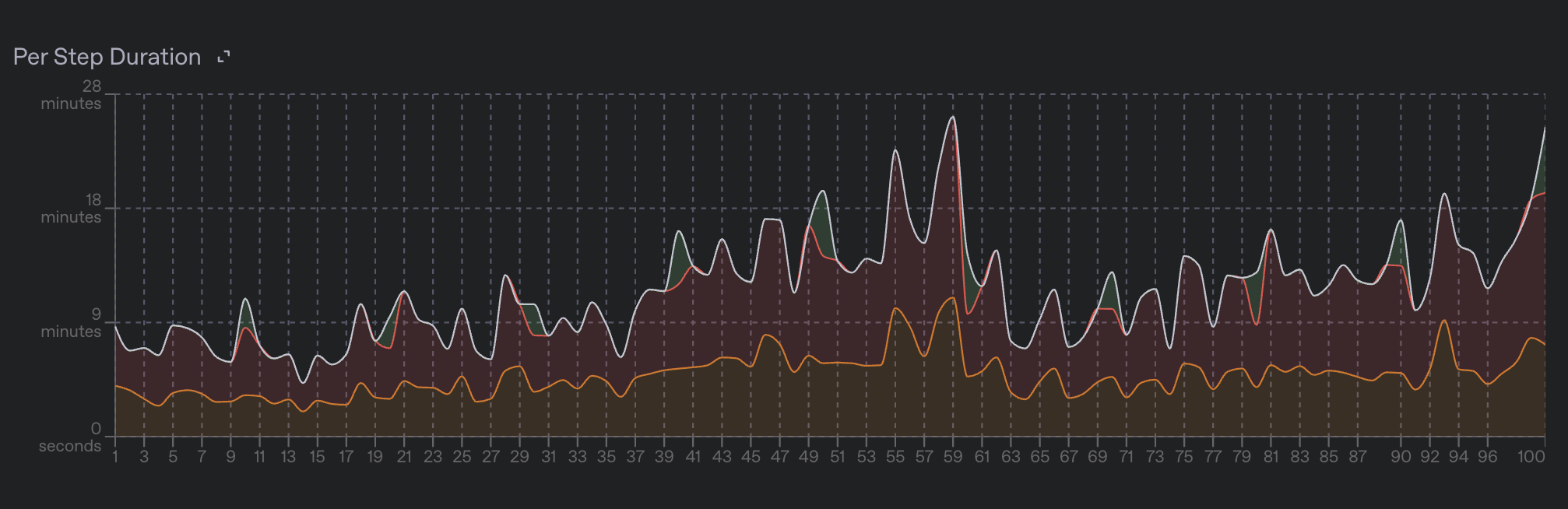
The graders field contains timing information that details the time taken to execute each grader for the current step. Each grader will have its own timing under the train_execution_latency_mean and valid_execution_latency_mean metrics, which represent the average time taken to execute the grader on the training and validation datasets, respectively.
Graders are executed in parallel with a concurrency limit, so it is not always clear how individual grader latency adds up to the total time taken for grading. However, it is generally true that graders which take longer to execute individually will cause a job to execute more slowly. This means that slower model graders will cause the job to take longer to complete, and more expensive python code will do the same. The fastest graders generally are string_check and text_similarity as those are executed local to the training loop.
Evals integration details
Reinforcement fine-tuning jobs are directly integrated with our evals product. When you make a reinforcement fine-tuning job, a new eval is automatically created and associated with the job.
As validation steps are performed, the input prompts, model samples, grader outputs, and more metadata will be combined to make a new eval run for that step. At the end of the job, you will have one run for each validation step. This allows you to compare the performance of the model at different steps, and to see how the model's behavior has changed over the course of training.
You can find the eval associated with your fine-tuning job by viewing your job on the fine-tuning dashboard, or by finding the eval_id field on the fine-tuning job object.
The evals product is useful for inspecting the outputs of the model on specific datapoints, to get an understanding for how the model is behaving in different scenarios. It can help you figure out which slice of your dataset the model is performing poorly on which can help you identify areas for improvement in your training data.
The evals product can also help you find areas of improvement for your graders by finding areas where the grader is either overly lenient or overly harsh on the model outputs.
Pausing and resuming jobs
You can pause a fine-tuning job at any time by using the fine-tuning jobs API. Calling the pause API will tell the training process to create a new model snapshot, stop training, and put the job into a "Paused" state. The model snapshot will go through a normal safety screening process after which it will be available for you to use throughout the OpenAI platform as a normal fine-tuned model.
If you wish to continue the training process for a paused job, you can do so by using the fine-tuning jobs API. This will resume the training process from the last checkpoint created when the job was paused and will continue training until the job is either completed or paused again.
Grading with Tools
If you are training your model to perform tool calls, you will need to:
- Provide the set of tools available for your model to call on each datapoint in the RFT training dataset. More info here in the dataset API reference.
- Configure your grader to assign rewards based on the contents of the tool calls made by the model. Information on grading tools calls can be found here in the grading docs
Billing details
Reinforcement fine-tuning jobs are billed based on the amount of time spent training, as well as the number of tokens used by the model during training. We only bill for time spent in the core training loop, not for time spent preparing the training data, validating datasets, waiting in queues, running safety evals, or other overhead.
Details on exactly how we bill for reinforcement fine-tuning jobs can be found in this help center article.
Training errors
Reinforcement fine-tuning is a complex process with many moving parts, and there are many places where things can go wrong. We publish various error metrics to help you understand what is going wrong in your job, and how to fix it. In general, we try to avoid failing a job entirely unless a very serious error occurs. When errors do occur, they often happen during the grading step. Errors during grading often happen either to the model outputting a sample that the grader doesn't know how to handle, the grader failing to execute properly due to some sort of system error, or due to a bug in the grading logic itself.
The error metrics are available under the event.data.errors object, and are aggregated into counts and rates rolled up per-grader. We also display rates and counts of errors on the fine-tuning dashboard.
Grader errors
Generic grading errors
The grader errors are broken down into the following categories, and they exist in both train_ (for training data) and valid_ (for validation data) versions:
sample_parse_error_mean: The average number of samples that failed to parse correctly. This often happens when the model fails to output valid JSON or adhere to a provided response format correctly. A small percentage of these errors, especially early in the training process, is normal. If you see a large number of these errors, it is likely that the response format of the model is not configured correctly or that your graders are misconfigured and looking for incorrect fields.invalid_variable_error_mean: These errors occur when you attempt to reference a variable via a template that cannot be found either in the current datapoint or in the current model sample. This can happen if the model fails to provide output in the correct response format, or if your grader is misconfigured.other_error_mean: This is a catch-all for any other errors that occur during grading. These errors are often caused by bugs in the grading logic itself, or by system errors that occur during grading.
Python grading errors
python_grader_server_error_mean: These errors occur when our system for executing python graders in a remote sandbox experiences system errors. This normally happens due to reasons outside of your control, like networking failures or system outages. If you see a large number of these errors, it is likely that there is a system issue that is causing the errors. You can check the OpenAI status page for more information on any ongoing issues.python_grader_runtime_error_mean: These errors occur when the python grader itself fails to execute properly. This can happen for a variety of reasons, including bugs in the grading logic, or if the grader is trying to access a variable that doesn't exist in the current context. If you see a large number of these errors, it is likely that there is a bug in your grading logic that needs to be fixed. If a large enough number of these errors occur, the job will fail and we will show you a sampling of tracebacks from the failed graders.
Model grading errors
model_grader_server_error_mean: These errors occur when we fail to sample from a model grader. This can happen for a variety of reasons, but generally means that either the model grader was misconfigured, that you are attempting to use a model that is not available to your organization, or that there is a system issue that is happening at OpenAI.