Fine-tuning
Fine-tune models for better results and efficiency.
Fine-tuning lets you customize a pre-trained model to excel at a particular task. Fine-tuning can be used with prompt engineering to realize a few more benefits over prompting alone:
- You can provide more example inputs and outputs than could fit within the context window of a single request, enabling the model handle a wider variety of prompts.
- You can use shorter prompts with fewer examples and context data, which saves on token costs at scale and can be lower latency.
- You can train on proprietary or sensitive data without having to include it via examples in every request.
- You can train a smaller, cheaper, faster model to excel at a particular task where a larger model is not cost-effective.
Visit our pricing page to learn more about how fine-tuned model training and usage are billed.
Fine-tuning methods
There are three fine-tuning methods supported in the OpenAI platform today.
|| |Supervised fine-tuning (SFT)+Vision fine-tuning|Provide examples of correct responses to prompts to guide the model's behavior. Often uses human-generated "ground truth" responses to show the model how it should respond.|ClassificationNuanced translationGenerating content in a specific formatCorrecting failures in instruction following for complex prompts| |Direct preference optimization (DPO)|For a prompt, provide both a correct and incorrect example response. Indicating the correct response helps the model perform better when the correct output is more subjective.|Summarizing text, focusing on the right thingsGenerating chat messages with the right tone and style| |Reinforcement fine-tuning (RFT)|Reasoning models only: Generate a response for a prompt, provide an expert grade for the result, and use the resulting score to reinforce the model's chain-of-thought for higher-scored responses. Works when expert graders can agree on the ideal output from the model.|Complex domain-specific tasks that require advanced reasoningMedical diagnosis based on history and diagnostic guidelinesDetermining relevant passages from legal case law|
How it works
In the OpenAI platform, you can create fine-tuned models either in the dashboard or with the API.
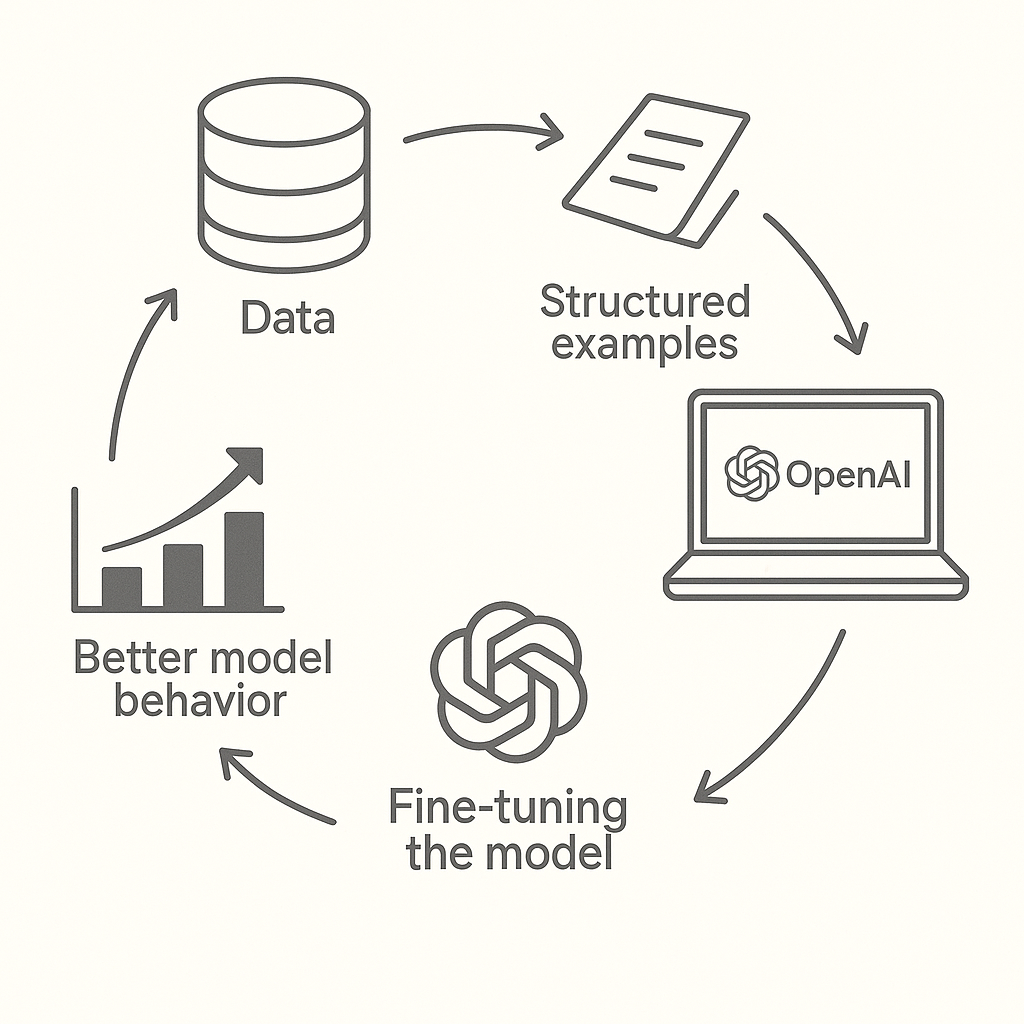
The general idea of fine-tuning is much like training a human in a particular subject, where you come up with the curriculum, then teach and test until the student excels. This is the general shape of the fine-tuning process:
- Collect a dataset of examples to use as training data
- Upload that dataset to OpenAI, formatted in JSONL
- Create a fine-tuning job using one of the methods above, depending on your goals—this begins the fine-tuning training process
- In the case of RFT, you'll also define a grader to score the model's behavior
- Evaluate the results
Fine-tuning is the process of adjusting a pre-trained model's weights using a smaller, task-specific dataset. OpenAI models are already pre-trained to perform across a broad range of subjects and tasks. Fine-tuning lets you take an OpenAI base model, provide the kinds of inputs and outputs you expect in your application, and get a model that excels in the tasks you'll use it for.
Get started
Follow the guides linked below for examples and more information about how to fine-tune models using each of these methods.
[
Supervised fine-tuning
Fine-tune a model by providing correct outputs for sample inputs.
](/docs/openai/guides/supervised-fine-tuning)[
Vision fine-tuning
Learn to fine-tune for computer vision with image inputs.
](/docs/openai/guides/vision-fine-tuning)[
Direct preference optimization
Fine-tune a model using direct preference optimization (DPO).
](/docs/openai/guides/direct-preference-optimization)[
Reinforcement fine-tuning
Fine-tune a reasoning model by grading its outputs.
](/docs/openai/guides/reinforcement-fine-tuning)