Voice agents
Learn how to build voice agents that can understand audio and respond back in natural language.
Use the OpenAI API and Agents SDK to create powerful, context-aware voice agents for applications like customer support and language tutoring. This guide helps you design and build a voice agent.
Choose the right architecture
OpenAI provides two primary architectures for building voice agents:
[

Speech-to-Speech
Native audio handling by the model using the Realtime API
](/docs/openai/guides/voice-agents?voice-agent-architecture=speech-to-speech)[

Chained
Transforming audio to text and back to use existing models
](/docs/openai/guides/voice-agents?voice-agent-architecture=chained)
Speech-to-speech (realtime) architecture

The multimodal speech-to-speech (S2S) architecture directly processes audio inputs and outputs, handling speech in real time in a single multimodal model, gpt-4o-realtime-preview. The model thinks and responds in speech. It doesn't rely on a transcript of the user's input—it hears emotion and intent, filters out noise, and responds directly in speech. Use this approach for highly interactive, low-latency, conversational use cases.
| Strengths | Best for |
|---|---|
| Low latency interactions | Interactive and unstructured conversations |
| Rich multimodal understanding (audio and text simultaneously) | Language tutoring and interactive learning experiences |
| Natural, fluid conversational flow | Conversational search and discovery |
| Enhanced user experience through vocal context understanding | Interactive customer service scenarios |
Chained architecture
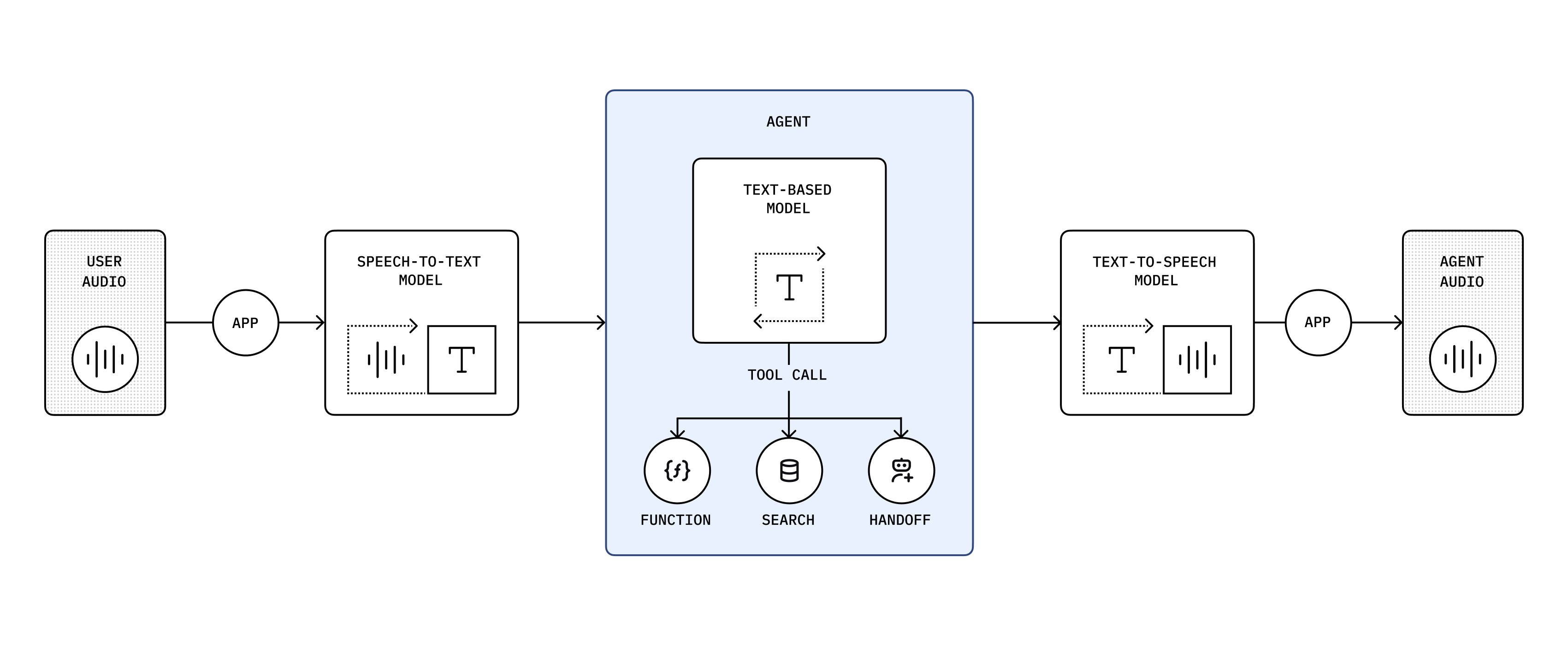
A chained architecture processes audio sequentially, converting audio to text, generating intelligent responses using large language models (LLMs), and synthesizing audio from text. We recommend this predictable architecture if you're new to building voice agents. Both the user input and model's response are in text, so you have a transcript and can control what happens in your application. It's also a reliable way to convert an existing LLM-based application into a voice agent.
You're chaining these models: gpt-4o-transcribe → gpt-4.1 → gpt-4o-mini-tts
| Strengths | Best for |
|---|---|
| High control and transparency | Structured workflows focused on specific user objectives |
| Robust function calling and structured interactions | Customer support |
| Reliable, predictable responses | Sales and inbound triage |
| Support for extended conversational context | Scenarios that involve transcripts and scripted responses |
The following guide below is for building agents using our recommended speech-to-speech architecture.
To learn more about the chained architecture, see the chained architecture guide.
Build a voice agent
Use OpenAI's APIs and SDKs to create powerful, context-aware voice agents.
Building a speech-to-speech voice agent requires:
- Establishing a connection for realtime data transfer
- Creating a realtime session with the Realtime API
- Using an OpenAI model with realtime audio input and output capabilities
To get started, read the Realtime API guide and the Realtime API reference. Compatible models include gpt-4o-realtime-preview and gpt-4o-mini-realtime-preview.
If you want to get an idea of what interacting with a speech-to-speech voice agent looks like, check out the example below.
[
Realtime API Agents Demo
A collection of example speech-to-speech voice agents including handoffs and reasoning model validation.
](https://github.com/openai/openai-realtime-agents)
Choose your transport method
As latency is critical in voice agent use cases, the Realtime API provides two low-latency transport methods:
- WebRTC: A peer-to-peer protocol that allows for low-latency audio and video communication.
- WebSocket: A common protocol for realtime data transfer.
The two transport methods for the Realtime API support largely the same capabilities, but which one is more suitable for you will depend on your use case.
WebRTC is generally the better choice if you are building client-side applications such as browser-based voice agents.
For anything where you are executing the agent server-side such as building an agent that can answer phone calls, WebSockets will be the better option.
Design your voice agent
Just like when designing a text-based agent, you'll want to start small and keep your agent focused on a single task.
Try to limit the number of tools your agent has access to and provide an escape hatch for the agent to deal with tasks that it is not equipped to handle.
This could be a tool that allows the agent to handoff the conversation to a human or a certain phrase that it can fall back to.
While providing tools to text-based agents is a great way to provide additional context to the agent, for voice agents you should consider giving critical information as part of the prompt as opposed to requiring the agent to call a tool first.
If you are just getting started, check out our Realtime Playground that provides prompt generation helpers, as well as a way to stub out your function tools including stubbed tool responses to try end to end flows.
Precisely prompt your agent
With speech-to-speech agents, prompting is even more powerful than with text-based agents as the prompt allows you to not just control the content of the agent's response but also the way the agent speaks or help it understand audio content.
A good example of what a prompt might look like:
# Personality and Tone
## Identity
// Who or what the AI represents (e.g., friendly teacher, formal advisor, helpful assistant). Be detailed and include specific details about their character or backstory.
## Task
// At a high level, what is the agent expected to do? (e.g. "you are an expert at accurately handling user returns")
## Demeanor
// Overall attitude or disposition (e.g., patient, upbeat, serious, empathetic)
## Tone
// Voice style (e.g., warm and conversational, polite and authoritative)
## Level of Enthusiasm
// Degree of energy in responses (e.g., highly enthusiastic vs. calm and measured)
## Level of Formality
// Casual vs. professional language (e.g., “Hey, great to see you!” vs. “Good afternoon, how may I assist you?”)
## Level of Emotion
// How emotionally expressive or neutral the AI should be (e.g., compassionate vs. matter-of-fact)
## Filler Words
// Helps make the agent more approachable, e.g. “um,” “uh,” "hm," etc.. Options are generally "none", "occasionally", "often", "very often"
## Pacing
// Rhythm and speed of delivery
## Other details
// Any other information that helps guide the personality or tone of the agent.
# Instructions
- If a user provides a name or phone number, or something else where you ened to know the exact spelling, always repeat it back to the user to confrm you have the right understanding before proceeding. // Always include this
- If the caller corrects any detail, acknowledge the correction in a straightforward manner and confirm the new spelling or value.You do not have to be as detailed with your instructions. This is for illustrative purposes. For shorter examples, check out the prompts on OpenAI.fm.
For use cases with common conversation flows you can encode those inside the prompt using markup language like JSON
# Conversation States
[
{
"id": "1_greeting",
"description": "Greet the caller and explain the verification process.",
"instructions": [
"Greet the caller warmly.",
"Inform them about the need to collect personal information for their record."
],
"examples": [
"Good morning, this is the front desk administrator. I will assist you in verifying your details.",
"Let us proceed with the verification. May I kindly have your first name? Please spell it out letter by letter for clarity."
],
"transitions": [{
"next_step": "2_get_first_name",
"condition": "After greeting is complete."
}]
},
{
"id": "2_get_first_name",
"description": "Ask for and confirm the caller's first name.",
"instructions": [
"Request: 'Could you please provide your first name?'",
"Spell it out letter-by-letter back to the caller to confirm."
],
"examples": [
"May I have your first name, please?",
"You spelled that as J-A-N-E, is that correct?"
],
"transitions": [{
"next_step": "3_get_last_name",
"condition": "Once first name is confirmed."
}]
},
{
"id": "3_get_last_name",
"description": "Ask for and confirm the caller's last name.",
"instructions": [
"Request: 'Thank you. Could you please provide your last name?'",
"Spell it out letter-by-letter back to the caller to confirm."
],
"examples": [
"And your last name, please?",
"Let me confirm: D-O-E, is that correct?"
],
"transitions": [{
"next_step": "4_next_steps",
"condition": "Once last name is confirmed."
}]
},
{
"id": "4_next_steps",
"description": "Attempt to verify the caller's information and proceed with next steps.",
"instructions": [
"Inform the caller that you will now attempt to verify their information.",
"Call the 'authenticateUser' function with the provided details.",
"Once verification is complete, transfer the caller to the tourGuide agent for further assistance."
],
"examples": [
"Thank you for providing your details. I will now verify your information.",
"Attempting to authenticate your information now.",
"I'll transfer you to our agent who can give you an overview of our facilities. Just to help demonstrate different agent personalities, she's instructed to act a little crabby."
],
"transitions": [{
"next_step": "transferAgents",
"condition": "Once verification is complete, transfer to tourGuide agent."
}]
}
]Instead of writing this out by hand, you can also check out this Voice Agent Metaprompter or copy the metaprompt and use it directly.
Handle agent handoff
In order to keep your agent focused on a single task, you can provide the agent with the ability to transfer or handoff to another specialized agent. You can do this by providing the agent with a function tool to initiate the transfer. This tool should have information on when to use it for a handoff. Here is an example of such a tool definition:
const tool = {
type: "function",
function: {
name: "transferAgents",
description: `
Triggers a transfer of the user to a more specialized agent.
Calls escalate to a more specialized LLM agent or to a human agent, with additional context.
Only call this function if one of the available agents is appropriate. Don't transfer to your own agent type.
Let the user know you're about to transfer them before doing so.
Available Agents:
- returns_agent
- product_specialist_agent
`.trim(),
parameters: {
type: "object",
properties: {
rationale_for_transfer: {
type: "string",
description: "The reasoning why this transfer is needed.",
},
conversation_context: {
type: "string",
description:
"Relevant context from the conversation that will help the recipient perform the correct action.",
},
destination_agent: {
type: "string",
description:
"The more specialized destination_agent that should handle the user's intended request.",
enum: ["returns_agent", "product_specialist_agent"],
},
},
},
},
};Once the agent calls that tool you can then use the session.update event of the Realtime API to update the configuration of the session to use the instructions and tools available to the specialized agent.
Extend your agent with specialized models
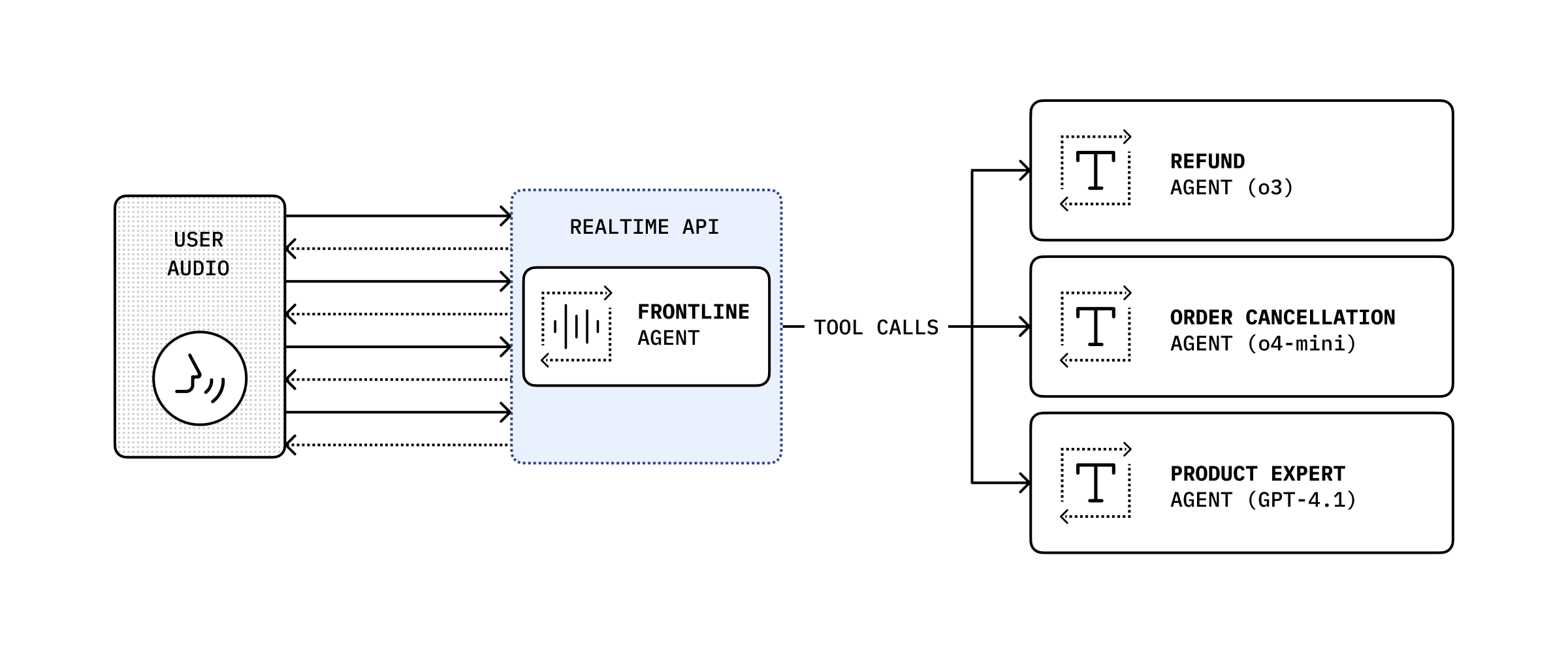
While the speech-to-speech model is useful for conversational use cases, there might be use cases where you need a specific model to handle the task like having o3 validate a return request against a detailed return policy.
In that case you can expose your text-based agent using your preferred model as a function tool call that your agent can send specific requests to.