关注AI的最近对5月28号的DeepSeek更新应该都有所耳闻,但真的像各种自媒体鼓吹的那样惊天地泣鬼神了吗?

DeepSeek-R1-0528升级总结
根据官方信息,DeepSeek-R1-0528是DeepSeek-R1模型的小版本升级。在官方网站、APP 或小程序进入对话界面,开启深度思考功能后才可体验。官方上下文长度仍为 64K,其他第三方平台上下文长度最长为 128K。
仍然使用2024 年 12 月所发布的 DeepSeek V3 Base 模型作为基座,但在后训练过程中投入了更多算力,显著提升了模型的思维深度与推理能力。
相较于旧版 DeepSeek-R1,新版DeepSeek-R1-0528在复杂推理任务中的表现有了显著提升。
根据官方测试数据,在AIME 2025基准测试中,新版模型准确率由旧版的 70% 提升至 87.5%,思考深度增加近一倍:
- 旧版模型平均每题使用 12K tokens,而新版模型平均每题使用 23K tokens
主要更新
深度思考能力强化
DeepSeek-R1-0528在数学、编程与通用逻辑等多个基准测评中取得了当前国内所有模型中首屈一指的优异成绩。整体表现上已接近其他国际顶尖模型,如 o3 与 Gemini-2.5-Pro。
o3 在2025.04.16发布,是OpenAI当前最强推理模型,擅长编码、数学、科学和视觉任务,最大200k上下文。
官方测评结果 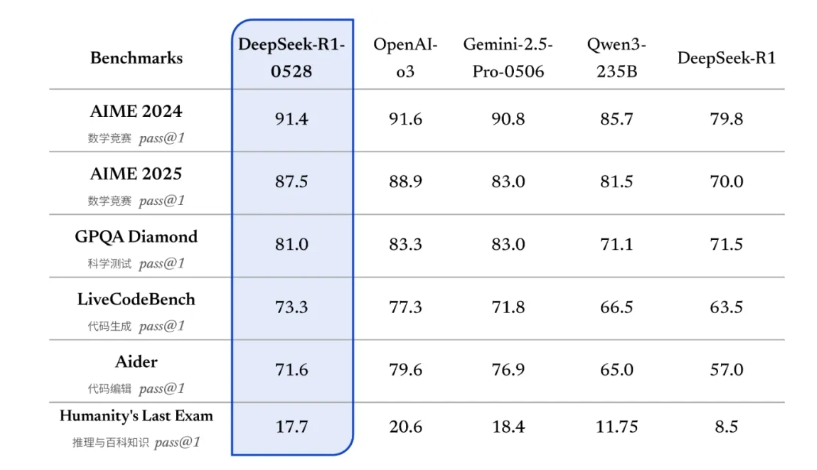
幻觉改善
DeepSeek-R1-0528针对"幻觉"问题进行了优化。根据官方内部测试,在改写润色、总结摘要、阅读理解等场景中,幻觉率较旧版降低了45-50%,能够有效地提供更为准确、可靠的结果。
创意写作
DeepSeek-R1-0528 模型针对议论文、小说、散文等文体进行了进一步优化,能够输出篇幅更长、结构内容更完整的长篇作品,同时呈现出更加贴近人类偏好的写作风格。
工具调用
DeepSeek-R1-0528 支持工具调用(不支持在 thinking 中进行工具调用)。当前模型 Tau-Bench 测评成绩为 airline 53.5% / retail 63.9%,与 OpenAI o1-high 相当,但与 o3-High 以及 Claude 4 Sonnet 仍有差距。
代码生成
DeepSeek-R1-0528 在前端代码生成、角色扮演等领域的能力均有更新和提升。
Last But Not Least
整体来看,确实有了不少提升,尤其是工具调用能更方便地与外部工具交互。
相对世界领先模型虽然还有差距,但是官方也非常地实事求是、脚踏实地。
在开源大模型领域仍然保持一骑绝尘。
愿DeepSeek越来越强大。ヾ(◍°∇°◍)ノ゙
Reference
- DeepSeek官方发布新闻 https://api-docs.deepseek.com/zh-cn/news/news250528
- OpenAI o3 and o4-mini https://openai.com/index/introducing-o3-and-o4-mini/
- OpenAI https://openai.com/api/
- Gemini2.5 https://blog.google/technology/google-deepmind/google-gemini-updates-io-2025